Proofreading symbols for e-texts or Wanted: A general annotation format!
(A modest proposal)
 Old-fashioned proofreading symbols for use on paper. The symbols are not the same in all countries. This kind is Swedish, although the text here is in English. (From Lansburgh, Sättningsregler, Uppsala, 1964.) |
There is (at least to my knowledge) no standard today for proofreading electronic documents. Since long, writers, editors, typesetters - and proofreaders - have had their own set of symbols for correcting errors, adding phrases etc. in paper based texts. But what to do when we communicate with editors and publishers via e-mail, or send text files on disk?
I believe there is need for a kind of markup standard for this purpose, especially since many people today do "dry" proofreading, that is without a paper original to compare with. For this people invent their own markup, using, for example, square brackets for text that should be deleted and maybe asterisks for new text. Some use the PDF or MS-Word format, where they may annotate, for instance with electronic "post-it notes". What would be more useful, however, is a non-proprietary system, that is possible to use in plain ASCII, for simple e-mail exchange etc. This simple markup would be easy to read for humans, but the system would also be machine-readable and easy to translate from the pure ASCII version into a kind of HTML tags.
The basics would be a standard for how to insert corrections with ordinary characters from the keyboard, characters not used anywhere else - at least not in the fashion we intend to adopt here - and the characters would also have to provide a good visible signal on the page, so that we don't miss anything when quickly skimming through a text, looking for corrections.
One such basic suggestion for ASCII could be to use say one, two and three asterisks (or #, Ł, $ or other custom character, that we may choose depending on whether it is already being used in the text at hand or not). Those asterisks would be used for 1) localization, as a sort of attention signal, 2) as a delimiter (to separate original text from corrections and comments). An example:
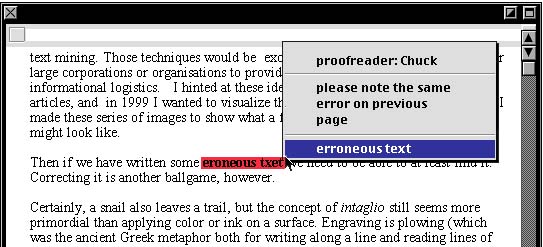
... if we have written some *eroneous txet ** erroneous text//please note the same error on previous page*** we need to be able to ...
The asterisks have a fairly good visibility on a page, which is needed since we are dealing with totally unformatted text - no colors, no boldface - in plain ASCII. Here the first asterisk indicates the beginning of a passage which needs correction. Then the double asterisks mark the end of that text and the beginning of the correct text, which is supposed to replace the incorrect passage.
Here, the corrective markup could be ended, and we would do that by typing three asterisks, thus closing the "tag". But, if we need to comment on the suggested correction, we might do so within the same space, between ** and ***, but now we need the two slashes as delimiters between the correct phrase and the comment. The idea is that the space between ** and *** will always contain information from the proofreader and the space between * and ** will always contain the original text that needs attention (and probably also correction).
This basic markup could be expanded to show how to move passages or whole paragraphs to other places etc. - all of those things the old paper symbols could do.
The idea is also that this rather crude system easily might be used also in HTML, so browsers or other parsers, such as plug-ins for word processors, could interpret the markup. The above example could be rendered in HTML thus:
... if we have written some <prf="some erroneous text" proofreaderscomment="please note the same error on previous page">eroneous txet</prf> we need to be able to ...
The HTML program in question might display the incorrect phrase in a certain color for instance, then doing a mouseover might pop up a menu with the phrase the proofreader has suggested. Then one might just choose it, and it would be inserted. Any comment will also be seen here, of course, and maybe also the name of the proofreader, which could come handy if several people have worked together on a document. This is what the pop-up menu could look like:
Furthermore, one might design a function that would allow one to enter counter-comments into the tags, if this document is supposed to be returned and discussed further, or if the document is to be circulated between several reviewers, it would be a possibility to discern different commentators' messages by different codes and/or colors. All these commentaries would be hidden, but displayed when the mouse is held over a passage marked with a certain color. Still, the same system might easily be used by someone who has access only to ASCII savvy programs. In a similar way as you can choose to save a web page as either source or text, you might be able to save an HTML proof document as either the original HTML proof or as ASCII with the simple asterisk markup.
The system allows for either manual corrections, or, if you for instance work closely with a certain proofreader and know that his/her suggestions are always reliable, you might automate the whole procedure. The program could be instructed to replace all the marked-up phrases with the new suggestions, all in one operation, like when you do search and replace in a word processor. Of course, the program could also in such cases - maybe for archival purposes - produce a special correction log, to show what has been done to the text.
I believe that this idea could possibly be expanded even more, since there is need for a more general annotation format for all electronic texts (and something similar also for images and sound). Maybe such an annotation format could be "embedded" in or "superimposed" on ASCII and possible to use in all formats. It would, so to speak, be stored on the "ASCII level" even in formatted word processor files, in PDF files - and even web pages could be commented with this mark-up, either just locally on one's own computer or submitted globally through future web services of some similar kind as Gooey, Odigo or Cahoots today.
I think the usefulness of e-books would be much enhanced if one could insert margin notes and commentaries in them, as easily as one does in printed books. As a matter of fact, I believe that a truly interchangeable non-proprietary e-book text format with a truly interchangeable non-proprietary mark-up standard for comments and proofreading is a necessity for e-books to really take on as an academic tool. Researchers and scholars don't wish for their marginal notes to be marooned on the pages of some seldom used e-book format.
To sum up: What started as an idea to convert old proofreading symbols into something that could be used for e-texts on the computer, did actually expand into something much more - really a kind of content based work process tool, which starts at the lowest level - a word or phrase or even a single character could be the target for comments, description and change. The system could be used to describe a document's modification history in detail, which is especially important today when the end product is often not the fixed printed copy, but a flexible electronic document that might never cease to change. Keeping track of who did what do which document is important for publishers and other people responsible for the accuracy and authenticity of information.
Today you might annotate a text in for instance a Word or an Adobe Acrobat file. You can print out the annotations separately. But you cannot do a global search of all those annotations, regardless of program or platform. With the general annotation format, you could search for instance for comments you made about, say, 'pathogens' with one single search operation that penetrates annotations made in word processor documents, in e-mail messages, in e-books, on web pages etc. You could even expand such a search to the web and read comments from other people who have read the same books as you.
The simple basic format of this standard would allow software companies to compete heavily by developing programs with lots of features. One program might just display the simple proofreading corrections, as showed in the fake screen dump above. Another company might design a very advanced tool, that could show statistics and error frequencies or link to second opinions in dictionaries or encyclopedias, or do a quick scan in some plagiarism database to help you check if a certain suspicious phrase might be stolen from another author, etc.
Many of these later ideas are of course inspired by Ted Nelson and others who have mused the possibilities of a docuverse. I believe that we indeed could create a sort of world brain - to borrow H.G Wells' expression - in the future, if the networks of humans and computers develop along lines like these.
But let's humbly start with at least something to mark up corrections in text files with!
Comments are welcome. Write to tallmo@nisus.se.
/Karl-Erik Tallmo
![]()
![]()
(August 2000, revised September 2001)![]()